
Apache Kafka is a distributed publish-subscribe messaging system that is designed to be fast, scalable, and durable. Kafka stores streams of records (messages) in topics. Each record consists of a key, a value, and a timestamp. Producers write data to topics and consumers read from topics.
Kafka Overview
Topics, Logs, Partitions and Offsets
Topics refer to a particular stream of data. It is similar to a table in a database. A topic is identified by its name.
For each topic, the Kafka cluster maintains a partitioned log. Topics are split in partitions. Each partition is ordered and each message within a partition gets and incremental identifier, called offset.
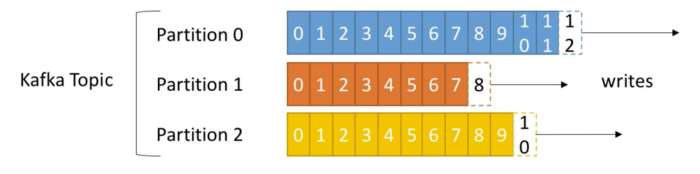
Offset only have a meaning for a specific partition. Order is guaranteed only within a partition (not across partitions).
Data is kept only for a limited time, called retention period, which is configurable. Once the data is written to a partition, it can not be changed.
Topics, Brokers and Replication
A Kafka cluster is composed of multiple brokers (servers). Each broker is identified by its ID and contains certain topic partitions.
Topics generally have a replication factor between 2 and 3 to replicate the data across multiple brokers. This way if a broker is down, another broker can serve the data.
In the picture below, there are three brokers with topic A having two partition with replication factor of 2.
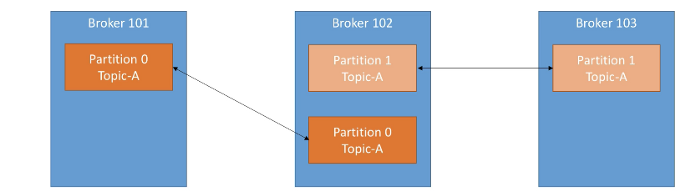
At any time, only one broker can be a leader for a given partition. Only leader can receive and send data for the partition. Leader is responsible for synchronizing the data with other brokers.
Producers and Message Keys
Producer write data to topics, which have multiple partitions. Producers automatically know to which broker and partition to write so that they recover automatically in case of broker failure.
A producer writes to multiple brokers based on key sent with the message. If no key is specified, producer writes to brokers in round-robin fashion. If key is sent, then all the message for that key will always go to the same partition. Producer load balances automatically across many brokers.
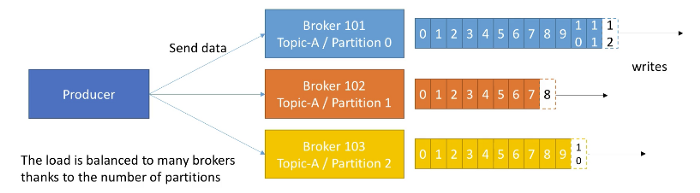
A producer can choose to receive acknowledge of data writes. There are three modes:
acks = 0— No acknowledgement (possible data loss)acks = 1— Leader acknowledgement (limited data loss) — Default optionacks = 2— Leader and all Replicas acknowledgement (no data loss)
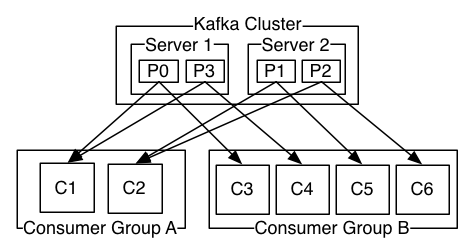
Consumer and Consumer Groups
Consumers read data from a topic, identified by name. Consumers know which broker to read from based on the key. In case of failures, consumers know how to recover. Data is read in order within each partition.
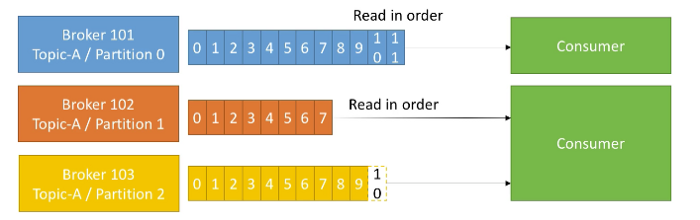
Consumers read data in consumer groups. Each consumer within a group reads from exclusive partitions. If you have more consumers than partitions, some consumers will be inactive.
Consumer groups can subscribe to one or more topics. Each one of these groups can be configured with multiple consumers.
Every message in a topic is delivered to one of the consumer instances inside the group subscribed to that topic. All messages with the same key arrive at the same consumer.
Consumer offsets and Delivery Semantics
Kafka stores the offsets at which a consumer group has been reading. These offsets are committed live in a Kafka topic named __consumer__offsets. This helps a consumer to read from where it left off in case it dies.
Kafka gives consumers to choose when to commit the offsets. There are three delivery semantics:
- At most once — offsets are committed as soon as the message is received. If processing goes wrong, the message is lost.
- At least once — offsets are committed after the message is processed. If processing goes wrong, the message will be read again. This can result in duplicate processing of messages.
- Exactly once — Can be achieved for Kafka to Kafka worflows using Kafka Streams API. It needs an idempotent consumer for external consumer workflow.
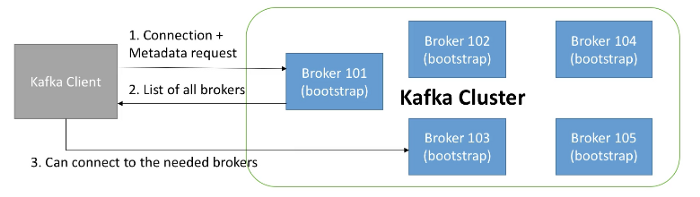
Kafka Broker Discovery
Every Kafka broker is also called a “bootstrap server” i.e. you only need to connect to one broker to connect to the cluster. Each broker knows about all brokers, topics and partitions (metadata). Following is typical exchange that happens when Kafka client connects to a Kafka Cluster.
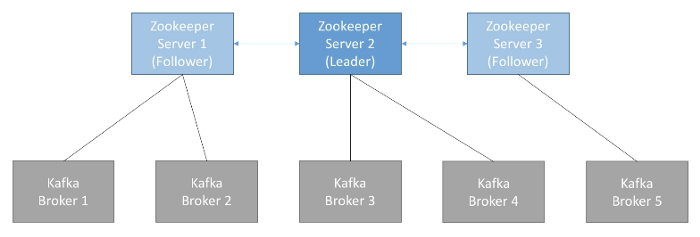
Zookeeper
Zookeeper manages brokers by keeping a list of them. It helps in performing leader election for partitions. It sends notifications to Kafka in case of changes (e.g. new topic, broker dies, broker comes up, delete topics etc.)
Zookeeper by design operates with an odd number of servers (3, 5, 7 …). Zookeeper has a leader (handle writes) and the rest of the servers are followers (handle reads).
Starting with Kafka and Zookeeper
Installation
- Download Kafka’s binary from official download page.
- Untar it to a directory using following command
tar -xvf kafka_2.12–2.5.0.tgzCalling this directory asKAFKA_DIRfor future reference. - Check it is running using
bin/kafka-topics.sh - Add the path to
PATHenvironment variable by editing.profilefile
Running
Go to the directory KAFKA_DIR and issue following commands:
Start Zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties
Start Kafka server
bin/kafka-server-start.sh config/server.properties
This is all that you need to start Zookeeper and Kafka server using default config.
Changing Default config
Zookeeper keeps the data in /tmp directory by default. I prefer to keep my data in different place. This can be done as follows:
- Create a directory
KAFKA_DIR/data/zookeeper - Update this path in
KAFKA_DIR/config/zookeeper.propertiesfor variabledataDir
Similarly, change the default location of kafka server logs directory as follows:
- Create a directory
KAFKA_DIR/data/kafka - Update this path in
KAFKA_DIR/config/server.propertiesfor variablelog.dirs
Using Kafka CLI
Use following commands after running zookeeper and kafka
Topics CLI
kafka-topics.sh --bootstrap-server localhost:9092 --topic first_topic --create --partitions 3 --replication-factor 1
kafka-topics.sh --bootstrap-server localhost:9092 --list
kafka-topics.sh --bootstrap-server localhost:9092 --topic first_topic --describe
kafka-topics.sh --bootstrap-server localhost:9092 --topic first_topic --delete
Console Producer CLI
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic first_topic
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic first_topic --producer-property acks=all
Just enter messages on >
Producer with keys
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic kv_topic --property parse.key=true --property key.separator=,
Console Consumer CLI
Only messages generated after consumer starts to consume.
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic first_topic
To read messages from beginning
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic first_topic --from-beginning
Using consumer groups
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic first_topic --group first-application
Consumer with keys
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic kv_topic --from-beginning --property print.key=true --property key.separator=,
Consumer Groups CLI
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group first-application
Reset offsets
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group first-application --reset-offsets --to-earliest --execute --topic first_topic
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group first-application --reset-offsets --shift-by -2 --execute --topic first_topic
Internals
To optimize the performance, one needs to understand how Kafka works internally. Here is a summary of few important design choices.
Storage
Kafka’s storage unit is a partition
Storage unit in Kafka is a partition, an append only ordered, immutable sequence of messages. A partition cannot be split across multiple brokers or even multiple disks.
Retention policy decides data retention
This data is retained for a specified amount of data or for specific duration based on configuration. After reaching either of the limit, Kafka purges messages in-order — regardless of whether the message has been consumed or not.
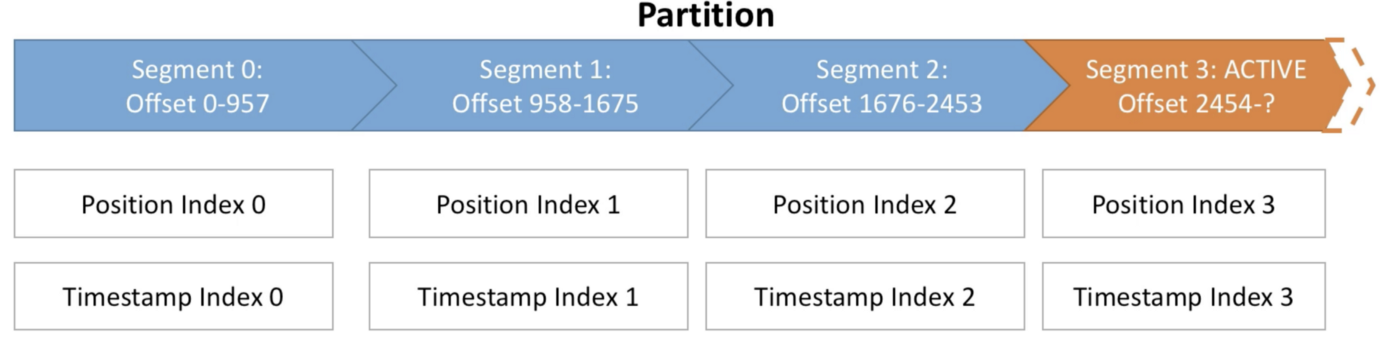
Partitions are split into segments
Kafka needs to regularly find the messages on disk that need to be purged. This operation is efficient if partition’s messages are stored in smaller segments (files) instead of a single big file.
On a partition, Kafka writes data to a segment — the active segment. When the segment’s size limit is reached, a new segment is started and that becomes the new active segment. Segments are named by their base offset. The base offset of a segment is an offset greater than offsets in previous segments and less than or equal to offsets in that segment.

Messages are stored in segment logs
The data format on disk is exactly the same as what the broker receives from the producer over the network and sends to its consumers, allowing for efficient data transfer. There are two segment settings:
log.segments.bytes: Maximum size of a single segment, in bytes.log.segments.ms: Maximum time for Kafka to wait before committing the segment, if not full.
Segment indexes map message offsets to their position in the log
Each segment comes with two indexes (files):
- An offset to position index: allows Kafka where to read to find a message
- A timestamp to offset index: allows Kafka to find messages with a timestamp
Log Compaction
Log Compaction ensures that the log contains at least the last known value for a specific key within a partition. This is very useful if the requirement is to just have a snapshot instead of full history.
This results in less time to recover as less reads are needed to reach to the final state. Log compaction has to be explicitly enabled on the topics of interest.
Reference:
- Apache Kafka Series — Udemy