
Here is a typical architecture having Sources, Sinks, Connect Cluster, Kafka Cluster and Kafka Streams Applications.
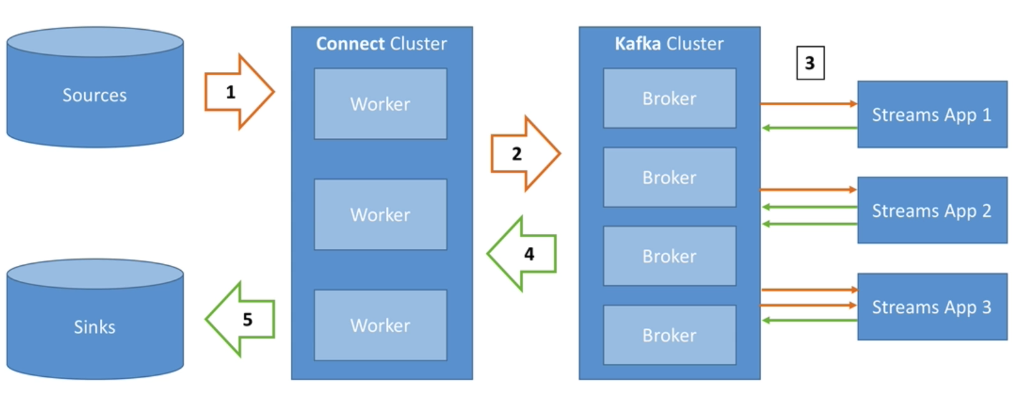
Kafka Cluster is made up of multiple brokers. There are Source(s) which we want to get data from and put in Kafka Cluster. In between comes Connect Cluster, which is made of multiple workers. Workers pull data from Sources [1] by specifying the Connector and corresponding configuration and uses the logic embedded in the connector. After getting the data, it pushes this data to Kafka Cluster [2].
Now, data may need to be transformed by transformation, aggregation, joins etc. This is done by using Kafka Stream APIs [3], which changes data in and out of Kafka. Last step is to put the data in Sinks done by Connect cluster by specifying the connector and corresponding configuration. It pulls the data out of Kafka Cluster and write to the Sink(s)[5].
Kafka Connect API
Kafka Connect APIs generally referred to as Kafka Connect simplifies interaction with Kafka for getting data in and out of it.
There are two form of Kafka Connect APIs:
- Kafka Connect Source — Programmers want to import data from finite number of similar sources e.g. Cassandra, DynamoDB, FTP, IOT, MQTT, Salesforce, Blockchain, Twitter etc.
- Kafka Connect Sink — Programmers want to export data to finite number of similar sinks e.g. ElasticSearch, Cassandra, DynamoDB, Twitter etc.
It is tough to achieve fault tolerance, exactly once, distribution, ordering by using the Kafka APIs. A lot of programmers have done a good job and provided the code in the form of various Connectors. It makes it easy for developers to quickly get their data in and out of Kafka with reliability and scalability.
Kafka Connect — Concepts
- Connectors — Kafka Connect Cluster has multiple loaded Connectors. Each connector is a reusable piece of code (e.g. java jars), generally available as open source.
- Tasks — Connector combined with configuration forms a Task. A task is linked to a connector configuration, which can create multiple tasks.
- Workers — Tasks are executed by Kafka connect Workers. A worker can run in stand alone mode, useful for development and testing. Workers can run in distributed mode, where multiple workers runs connectors and tasks, for fault tolerance and horizontal scalability.
Kafka Stream API
Kafka stream APIs is a library within Kafka for easy data processing and transformation. In other words, Kafka Streams is a library for developing applications for stream processing where the data is in topics in Apache Kafka. It is a standard Java application and there is no need to create a separate cluster. It is highly scalable, elastic, fault tolerate and provides exactly once capabilities. I processes one record at a time, no batch processing.
Kafka Stream — Concepts
Stream — A stream is a sequence of immutable data records, that fully ordered, can be replayed, and is fault tolerant.
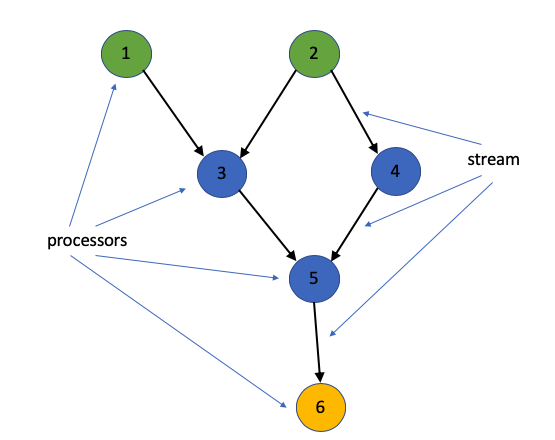
Stream Processor — A stream processor is a node in the processor topology. It transforms incoming streams, record by record and may create a new stream from it. There are two type of special processors:
- Source Processor is a processor that takes its data directly from a Kafka topic. It has no predecessors in a topology and does not transform data. In the topology shown below, node 1 and 2 are source processors.
- Sink Processor is a processor that does not have children. It sends the stream data directly to Kafka topic. In the topology shown below, node 6 is the sink processors.
Topology — A topology is a graph of processors chained together by streams.
Multi-instance Kafka Streams Applications
A single Kafka Streams application can be executed in a group of stream processing nodes that are identified by the same application identifier. The stream processing clients may run on the same physical machine or separate nodes. As per Kafka cluster, the instances all together act as a consumer group.
KStreams and KTables
KStreams is an all inserts unbounded data stream. It is similar to an infinite log. On the other hand, KTables is all upserts on non-null values. It deletes on null values. It is similar to a table and similar to log compacted topics. Here is a comparison between two.
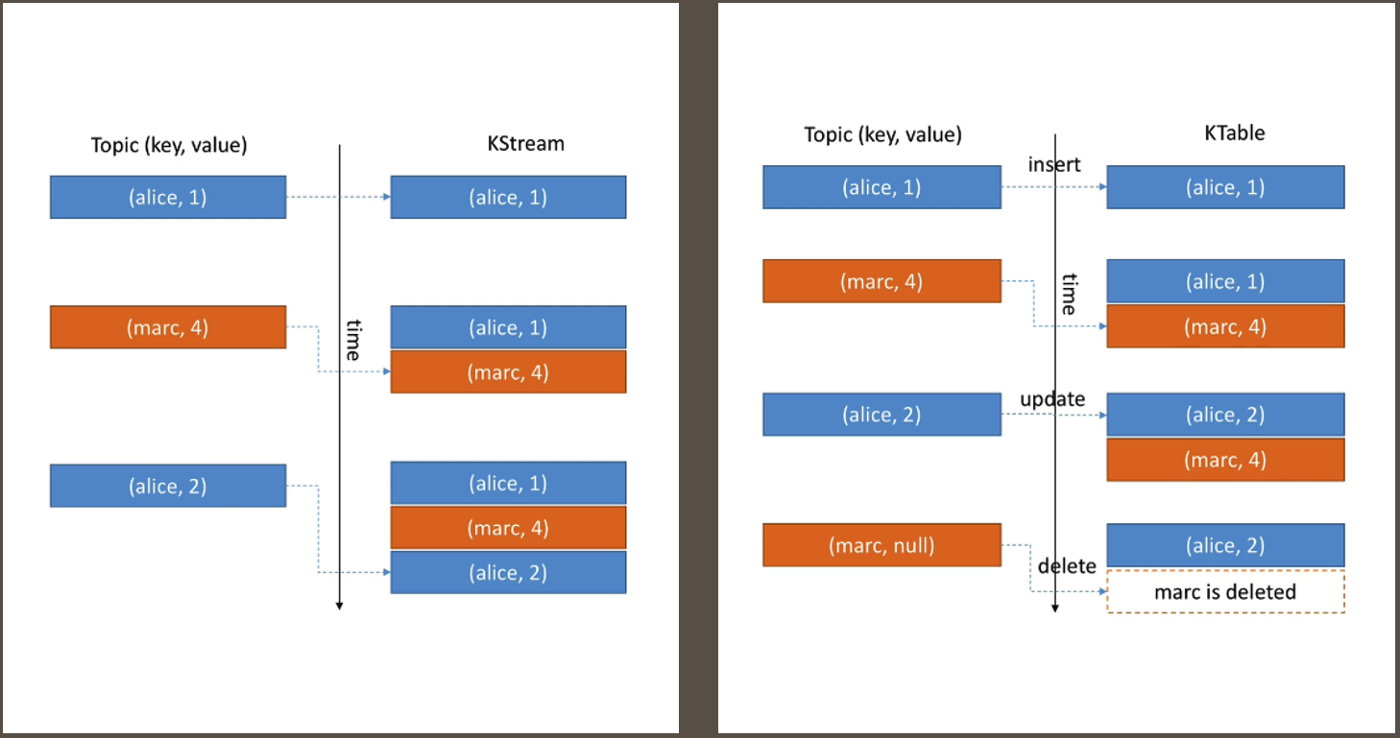
When to use KStream vs KTable?

KStream and KTable duality refers to the fact that KStream can be converted to KTable and vice versa, which is very useful.
Exactly Once Semantics (EOS)
Exactly once is the ability to guarantee that data processing on each message happens only once, and that pushing the message back to Kafka also happens effectively only once. Kafka does de-duplication in case multiple delivery happens. There are two restrictions:
- It is guaranteed when both input and output system is Kafka, not for Kafka to any external systems.
- Kafka brokers and Kafka Streams client should be of version ≥ 0.11
What is the problem EOS solve ?
In case of a failure, message is received more than once. This happens data processing to happen multiple times. This is not acceptable in certain cases e.g. Summing up bank transactions to compute a person’s bank balance.
To understand what can cause this problem, consider the scenario where Kafka Streams producer and consumer are interacting with Kafka cluster. For simplicity, Kafka cluster is shown at two ends, though it refers to the same Kafka cluster.

There are two cases where message is received more than once:
- Failure after step #3.
As a Kafka Consumer same message is received twice if the Kafka broker reboot or Kafka Consume restarts (because of least once behaviour). This is because offsets are committed once in a while, but data may have been processed already
- Network failure after step #2
As a Kafka Producer, same message is sent twice to Kafka if ACK is not received from Kafka (because of the retry logic). But this may result in duplicate message to Kafka as ACK may not be received due to network failure.
How does Kafka solve this problem?
On a high level, this problem is solved by following changes:
- Producers are now idempotent.
- Multiple message are written to different Kafka topics as part of one transaction.
EOS has a performance impact of 10 to 20 percent
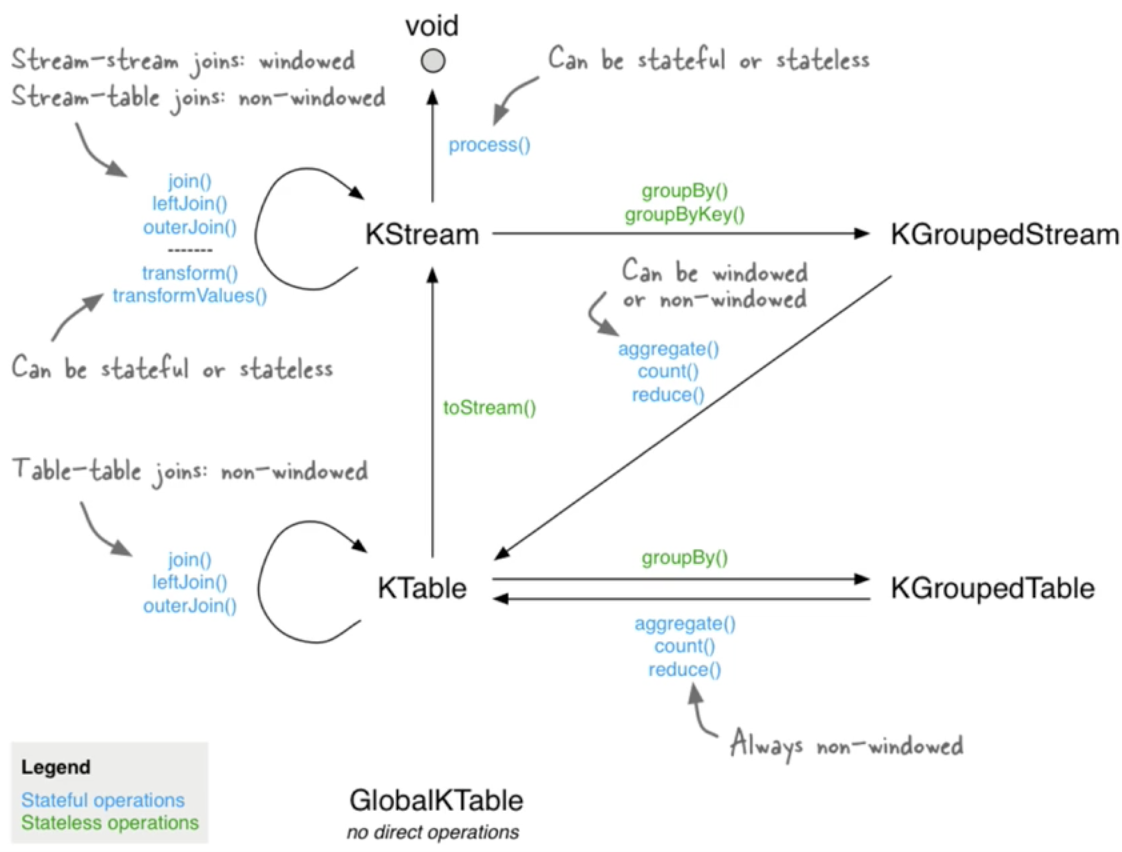
Joins
Kafka Streams supports three kinds of joins:
- Inner Joins: Emits an output when both input sources have records with the same key.
- Left Joins: Emits an output for each record in the left or primary input source. If the other source does not have a value for a given key, it is set to null.
- Outer Joins: Emits an output for each record in either input source. If only one source contains a key, the other is null.

Detailed article is available at Confluent.
Reference:
- Confluent
- Apache Kafka Series — Udemy