
Initially software applications were small which can be deployed on a single computer. Over a period of time, data volume processed by these application grew in size. Hence, the requirement for storage and computing power grew. These requirements were fulfilled by rapid advancements in storage and compute hardware by having larger disks and faster CPUs. This way of scaling is termed as vertical scaling, which soon became costlier when applications started being consumed over Internet.
With Internet scale, the data processing and compute need started growing exponentially, which can’t be solved with vertical scaling any more. Google solved these problems and published the results as Google File System (GFS) and MapReduce. GFS solved the storage problem by implementing a distributed file system over a cluster of computers. Similarly, MapReduce solved the compute problem by implementing a distributed processing framework over GFS. These formed the basis for similar open source systems named HDFS (Hadoop Distributed File System) and Hadoop MapReduce. These frameworks allowed to combine the storage and compute power of cluster of computers and use it as unified storage and compute system, known as horizontal scaling.
There are many solutions developed over Hadoop platform and open sourced. Apache Spark is one of these solutions, which provides unified programming model in multiple languages. It is used extensibly in Big Data and Machine Learning.
Data Lake basics
Data Lake refers to a platform with four key capabilities namely, Ingest, Store, Process and Consume. Following figure shows options for different layers in a data lake.
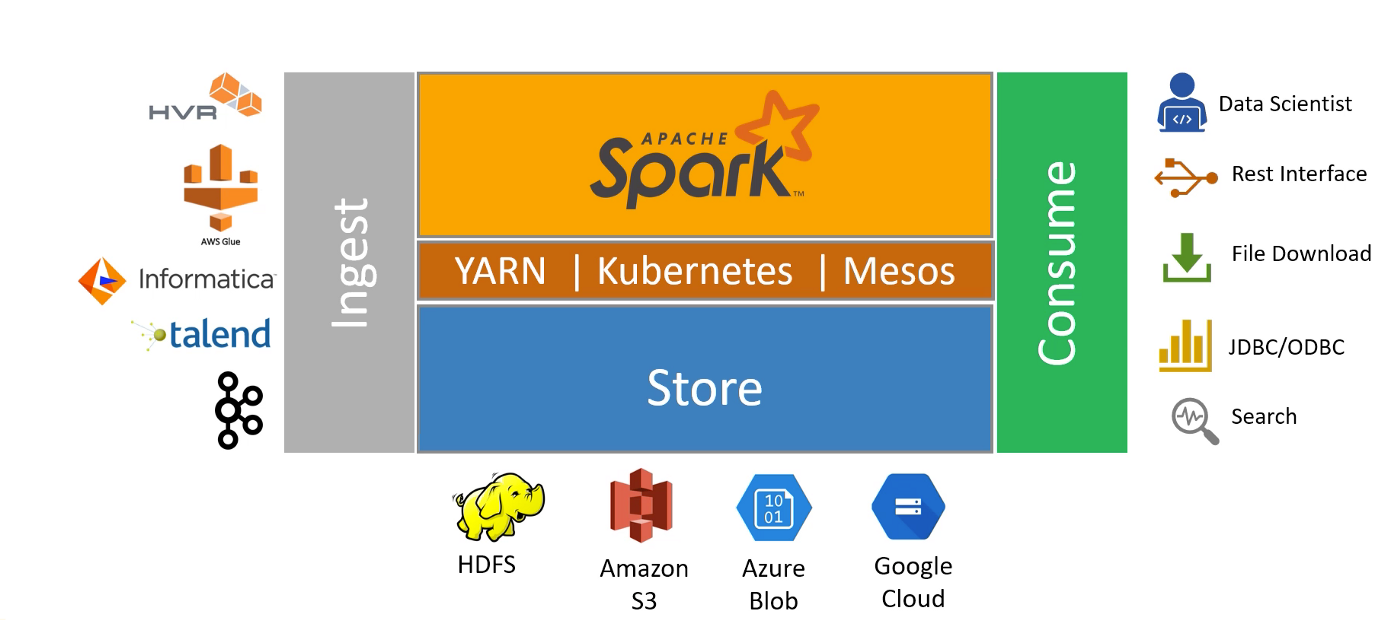
Data Storage and Management is provided by many on-premise HDFS or cloud storage solution like Amazon S3, Azure Blob, Google Cloud.
Data Collection and Ingestion is the premise that the data should be ingested in data lake in “raw” format and an immutable copy should be saved. Ingestion is provided by various tools as like HVR, AWS Glue, Informatica, talend and Kafka.
Data Processing and Transformation is done after data quality check. This layer is divided into two layers:
- Data Processing framework is the core development framework that allows to develop distributed application. Apache Spark is one of the data processing framework.
- Orchestration framework forms and manages the cluster to provide a scalable compute platform. There are many frameworks like Hadoop YARN, Kubernetes and Mesos.
Data Access and retrieval allows one to consume data from data lake. There are various formats in which data is requested by consumers like REST interface, JDBC/ODBC or simple file download.
Spark Basics
Apache Spark is a unified analytics engine for large-scale data processing. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for incremental computation and stream processing.
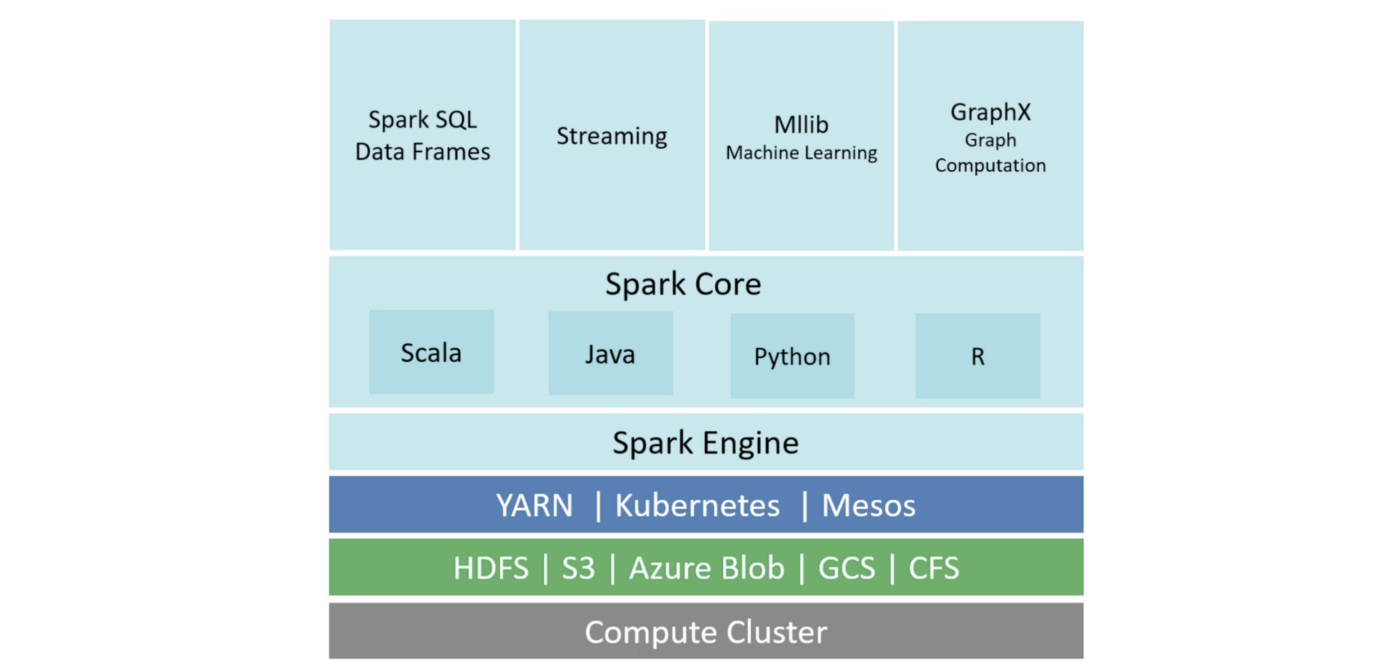
Spark neither has a distributed storage system or a cluster manager
It works with other distributed storage systems (e.g. HDFS, S3 etc) and cluster managers (e.g. YARN, Kubernetes, Mesos). Spark provides only the data processing framework.
Spark engine provides the following capabilities:
- Breaking data processing work into smaller tasks
- Scheduling smaller tasks on the cluster for parallel execution
- Providing data to these tasks
- Managing and monitoring these tasks
- Providing fault tolerance when job fails
Spark Engine interacts with cluster manager and distributed storage system to provide above capabilities
Spark Architecture
There are two ways to run Spark programs.
- Interactive Clients runs spark program line by line. Interactive clients are useful for exploration during learning or development phase. Examples of interactive clients are: spark-shell, notebook
- Submit Jobs is used in production. There could be either stream processing jobs or batch processing jobs. Examples: spark-submit, Databricks Notebook, Rest API
Distributed Processing Model
Spark applies master-slave architecture to every application. When spark client submits an application, it creates a master process for the application. This master process then creates bunch of slaves to distribute the work and compute the jobs. Master and slaves are containers with dedicated memory and CPU. In spark terminology, master is called driver and slaves are called executors. Each application has one driver and one or more executors.
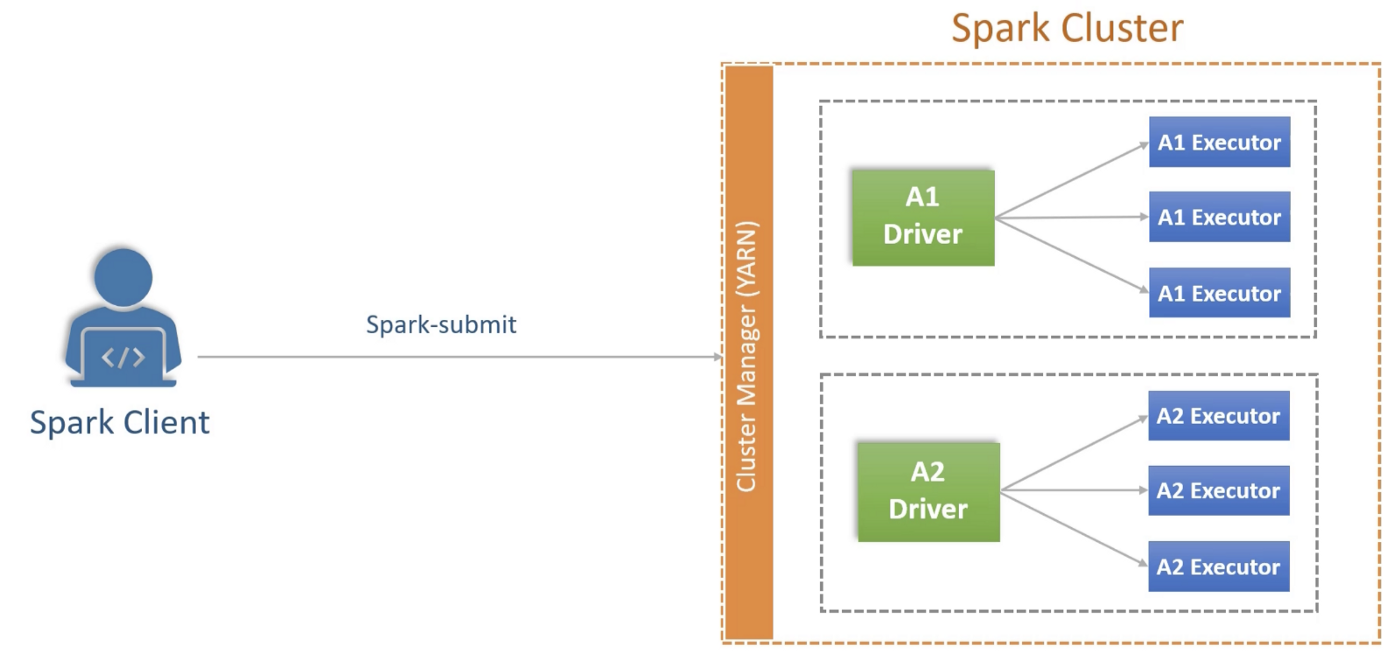
Spark master (driver) and slaves (executors) are different from the underlying “Cluster Manager”, which has its own terminology for master and slave nodes
Spark supports following cluster managers:
- local[n]
- YARN
- Kubernetes
- Mesos
- Standalone
How Spark works on Local Machine?
Local execution is supported with cluster option local[n]. In this cases, spark runs locally as a multithreaded application. There is 1 driver thread and n-1 executors threads.
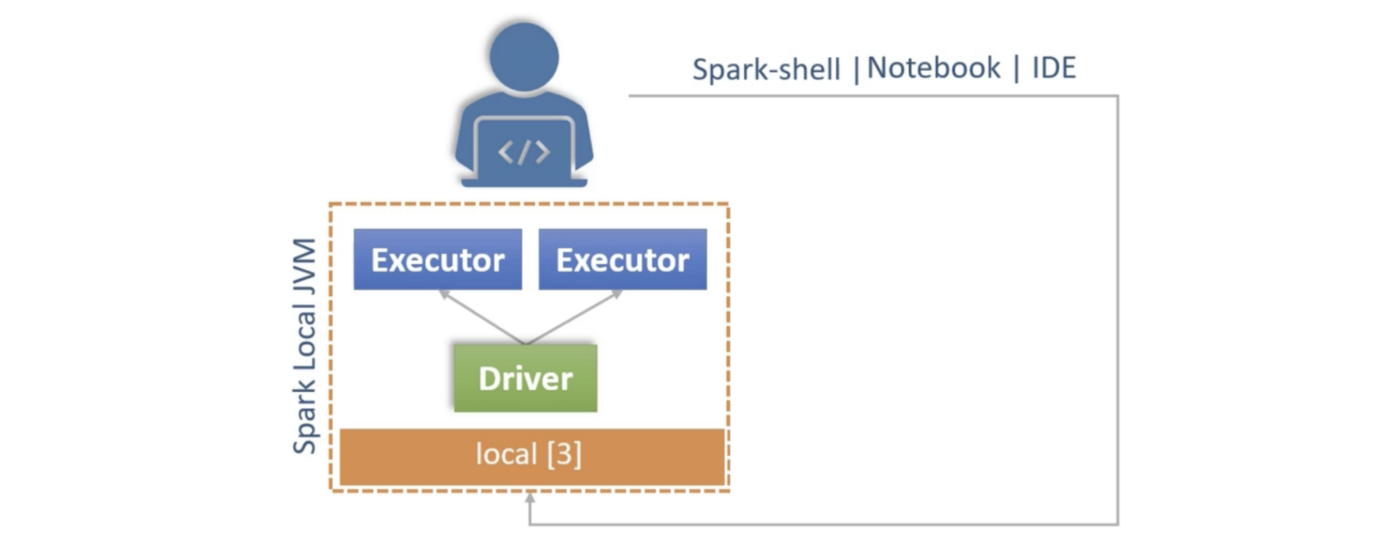
How Spark works with Interactive Clients?
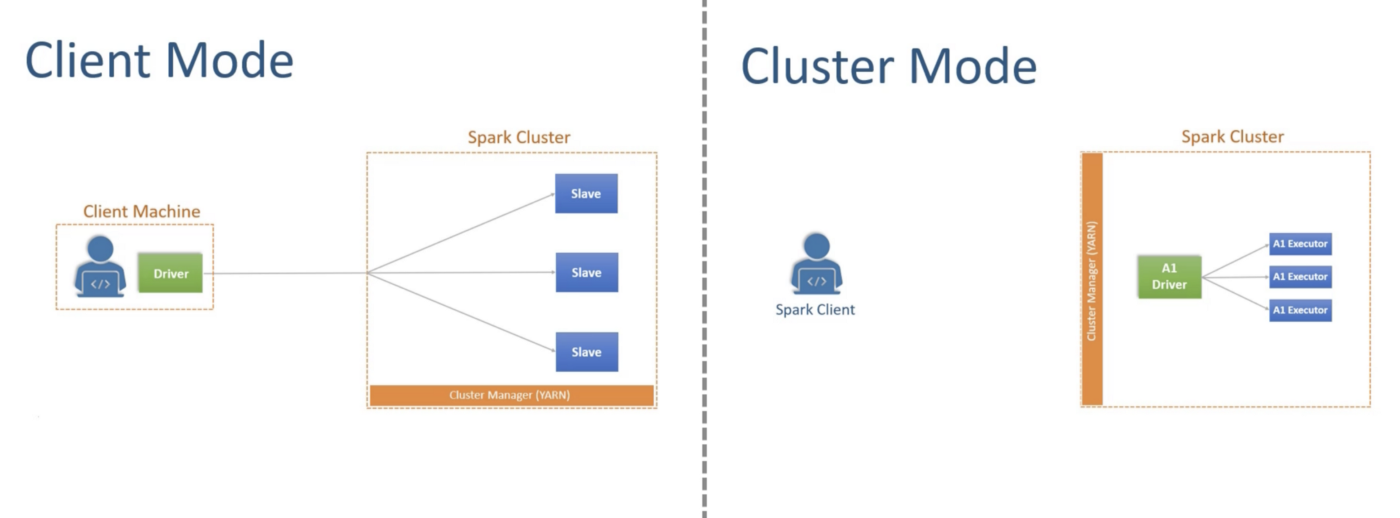
Spark support two deployment modes:
- Client Mode is designed for interactive clients. In this mode, Spark driver process runs at client machine and connects to cluster manager to start the executors at the cluster. This is how the interactive clients are working. The problem with this mode is that in case client machine fails, driver as well as executors will die.
- Cluster Mode is designed to submit application to the cluster and let it run on cluster. In this mode, driver as well as executors runs at cluster.
Programming Model
Each Spark application has exactly one active session object, which is a singleton object. Spark session can be viewed as the Spark driver and it is the first thing to be created in a Spark program.
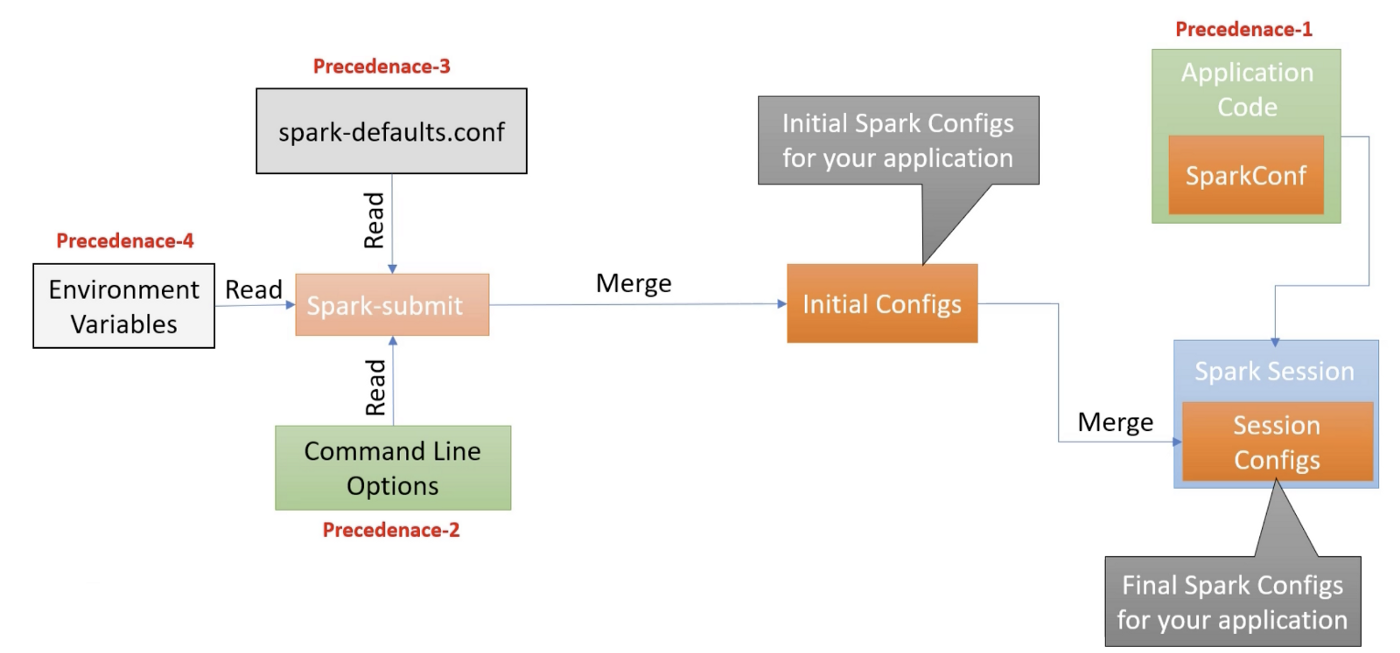
Spark is a highly configurable system. Configuration is allowed using four different methods having different precedence.
- Environment Variables
spark-defaults.conffilespark-submitcommand line options- SparkConf Object
Spark Data Frame — Reading Data
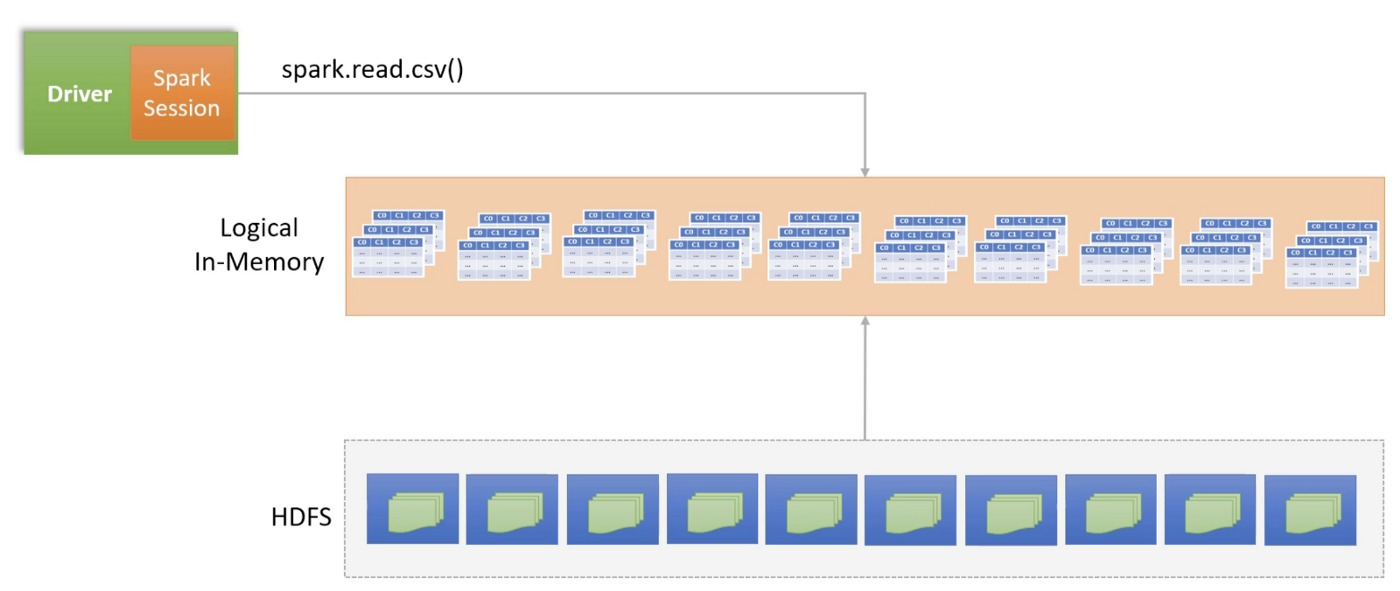
Spark data frame is a distributed two dimensional table with named columns and well defined schema (each column has a specific data type). Spark uses data frames for distributed processing of data.
Data is generally stored in a distributed file system e.g. HDFS or Amazon S3. These system partition the data file and store those partitions across the distributed storage nodes.
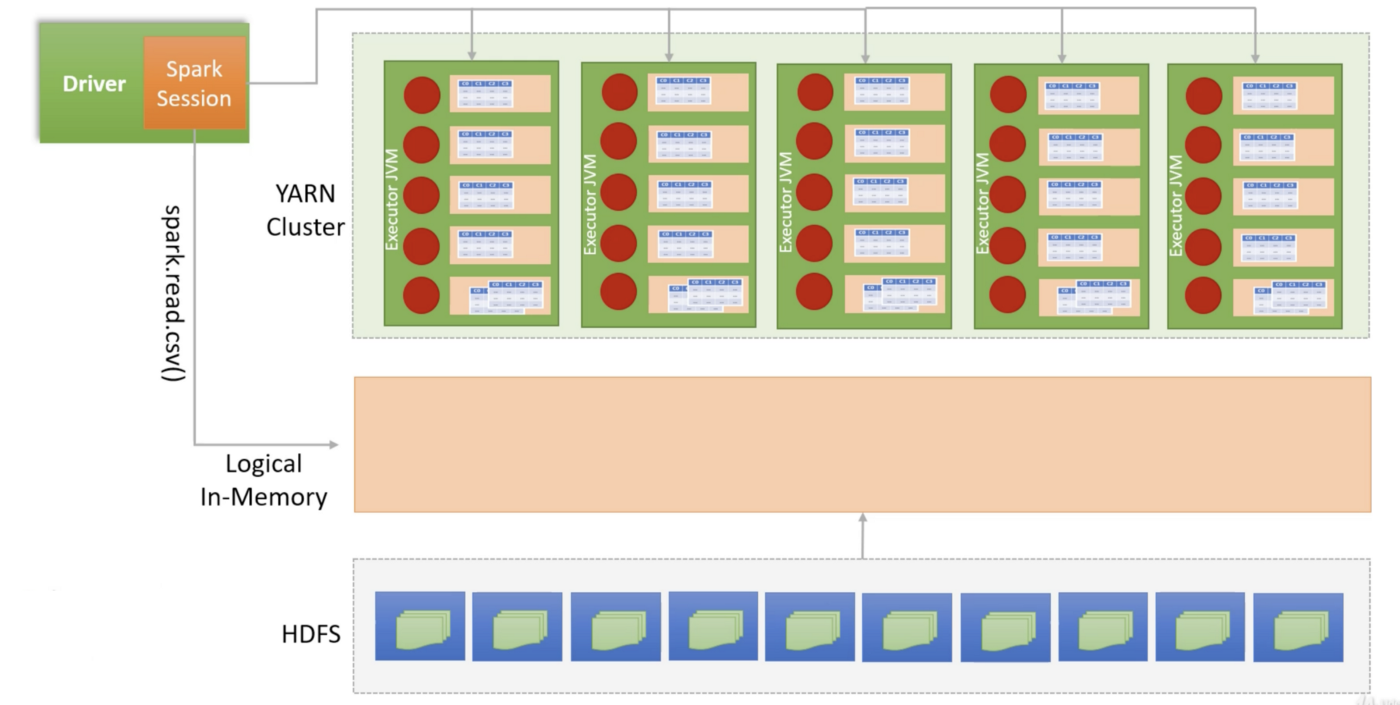
Spark data frame reader reads storage system partitions as logical in-memory partitions. It is done by the Spark driver after consulting the cluster manager and storage manager. At this stage nothing is loaded in memory. It is just the logical structure with enough information to load it.
Spark driver knows about the configuration of spark executors in terms of memory and CPU cores. Spark driver requests cluster manager for the containers in order to start Spark executors in them. Spark driver distributes the work by assigning some partitions to each executor, which in turn load the respective partition in their memory.
Spark Transformations — Processing Data
- Transformations — operations used to transform an input data frame into an output data frame without modifying the input data frame (e.g. where transformation). Transformation are further divided into two types. A transformation performed independently on a single partition to produce valid result is called a Narrow Dependancy transformation (e.g. where transformation). On the other hand, a transformation that require data from other partitions to produce correct results is called a Wide Dependancy transformation (e.g. groupBy transformation).
- Actions — operations that lets you READ, WRITE, COLLECT or SHOW the data are actions. Spark driver uses lazy evaluations to rearrange operations to build an optimized execution plan, which is executed by the executors. Actions terminates the execution DAG and triggers execution.
Transformations are lazy but Actions are evaluated immediately.
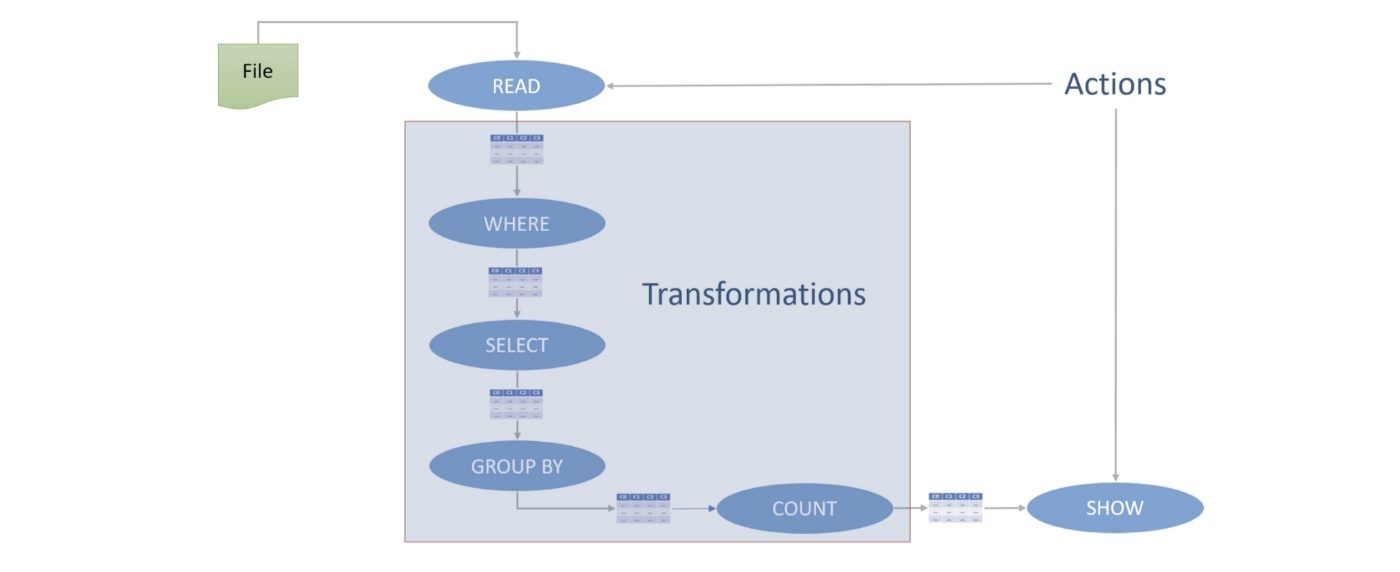
Shuffle/Sort Exchange
Any aggregation after wide dependancy transformation (e.g. groupBy) will produce incorrect result. This can be fixed by repartitioning the grouped data so as to combine all partitions and repartition the data such that all records from the same groups are in the same partition. This operation is called shuffle and sort exchange.
Spark Execution Plan
Spark has a compiler, which takes the higher level code and converts it to generate low level Spark code and creates an execution plan Execution plan is accomplished using jobs, stages and tasks.
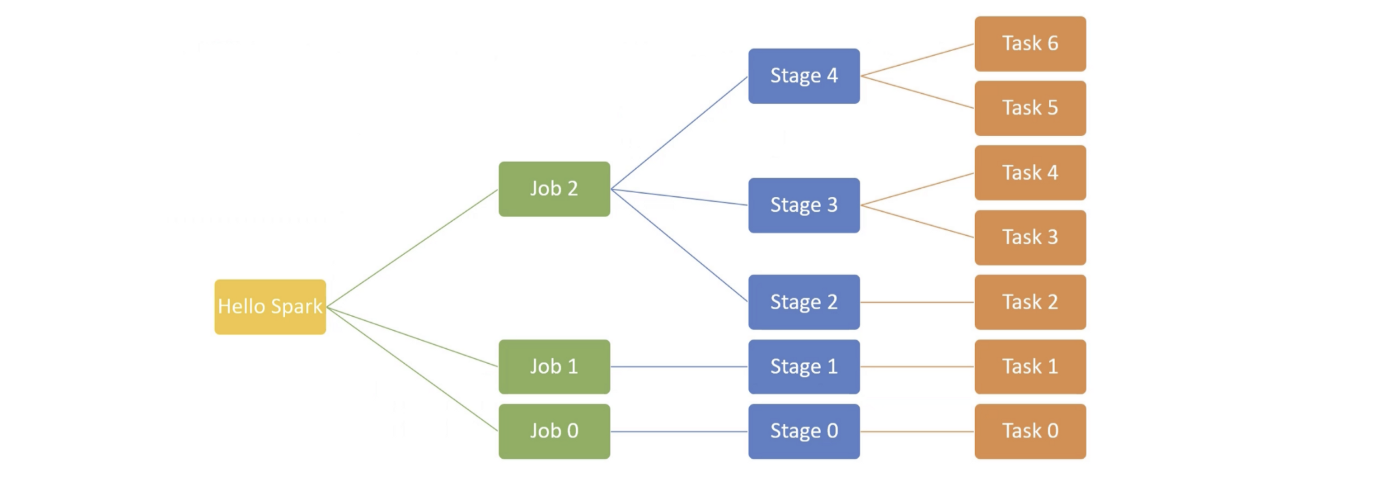
Spark application is compiled into multiple jobs. Each job has multiple stages and each stage has one or more tasks. Task is the unit of work assigned to executors.
- Every action results into a job (e.g. loading the data into data frame). Any internal action may lead to additional jobs (e.g. inferring a schema during read will lead to one more job)
- Each wide dependancy transformation results in a stage. Spark creates a DAG for each job and break it into multiple stages separated by shuffle/sort operation (e.g. groupBy).
- Every stage executes multiple tasks in parallel depending on number of data frame partitions.
Spark APIs
Spark has a basic notion of RDD API, which creates the core foundation. Spark has higher layer API such as Dataframe API and Dataset API. To simply it further, Spark has a Spark SQL API and Catalyst Optimizer.
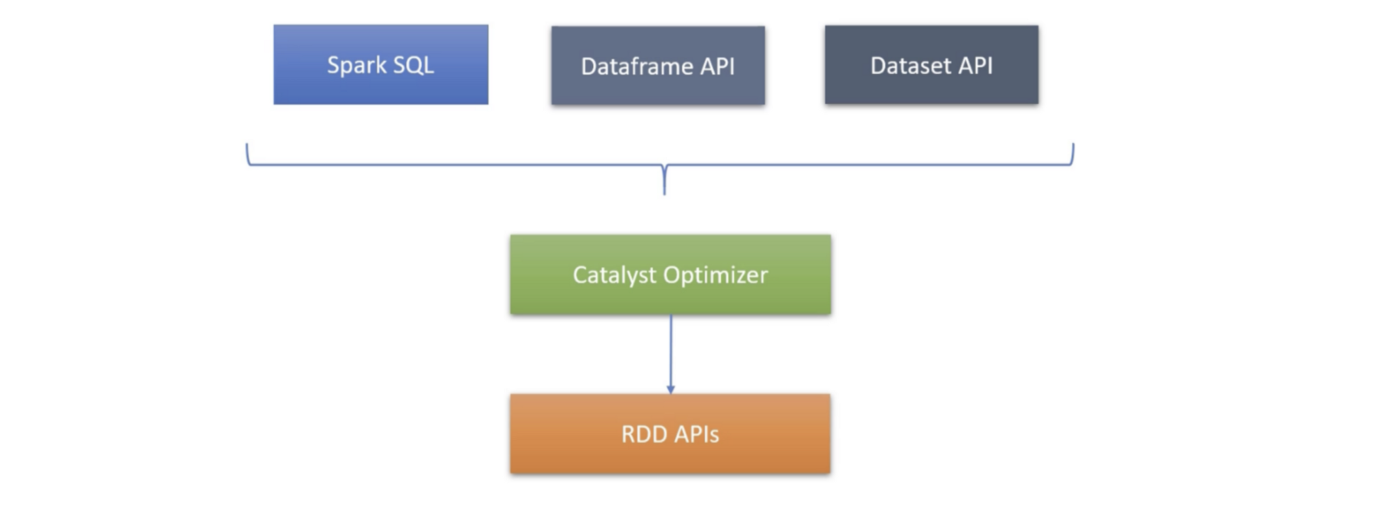
RDD API can be used to develop applications but it is most challenging to learn and develop. It offers most flexibility but lacks the optimization brought in by Catalyst Optimizer. Spark community does not recommend using RDD API.
Preferred option is to use Spark SQL, Dataframe API and Dataset API in the order from left to right. This code is optimized by Catalyst Optimizer to create an execution plan. Note that dataset APIs are language native APIs in Scala and Java and are not available in dynamically typed languages like Python.
Resilient Distributed Dataset (RDD)
RDD is a dataset to hold data records. They are similar to data frames, which are built on top of RDDs. But unlike data frames, RDDs are language native objects i.e. they do not have row-column structure and a schema. In other words, RDD is a Scala, Java or a Python collection. RDD is internally broken down into partitions to form a distributed collection.
RDDs are resilient i.e. they are fault tolerant. This is achieved by having information associated with each RDD for its creation and processing. In case of executor failure, driver can reassign the RDD to another executor and that executor can load the RDD using the associated information.
Spark Data Processing
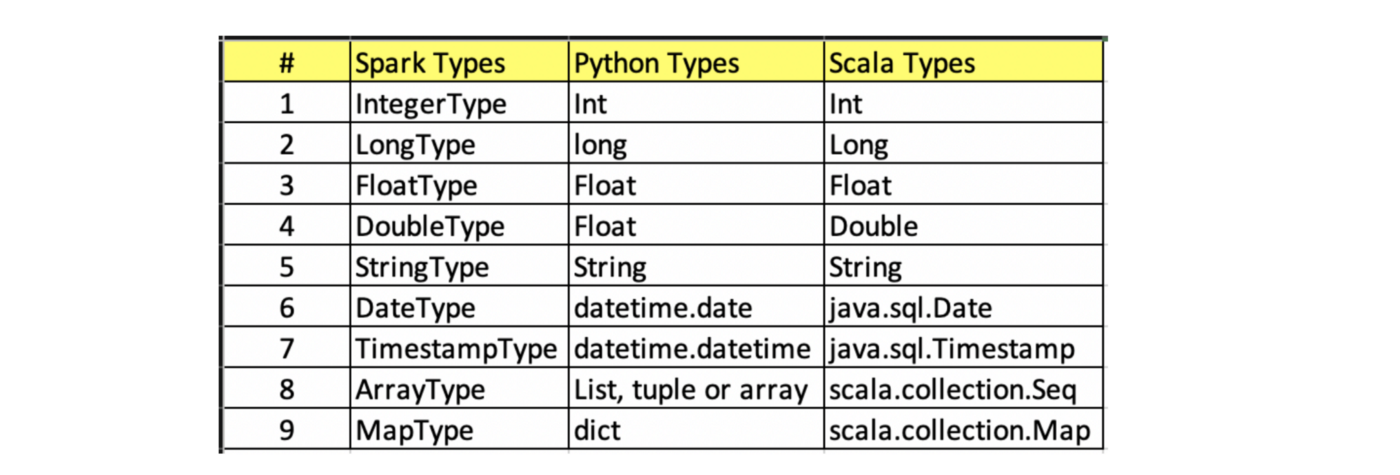
Data Types
Following are mapping of common data types to Python and Scala.
Data Sources and Data Sinks
Spark is used for processing large volumes of data. The data must be read from a data source. These data sources are categorized in two groups:
- External Data Sources — data sources existing outside data lake.
- Internal Data Sources — distributed storage like HDFS or cloud based storage (e.g. S3).

Data Sinks are the final destination of the processed data.

Spark Databases and Tables
Apache Spark, apart from being a set of APIs and processing engine, is a database in itself. Database can be created in Spark. Inside the database, tables and views may be created. Table has two parts:
- Table Data stored as data files in the distributed file storage having default file format of parquet.
- Table Metadata stored in a meta-store called catalogue. It stores the information about the table and its data such as schema, table name, database name, column names, partitions and physical location where actual data resides.
By default, Spark comes with an in-memory catalogue maintained per Spark session, which is not persistent when session ends. Apache Hive meta-store is used for persistent datastore.
Spark supports two type of tables:
- Managed Tables — Spark manages both metadata and data. The data is stored in Spark warehouse using predefined directory location (
spark.sql.warehouse.dir). - Unmanaged Tables (External Tables) — Spark manages metadata similar to managed table. Data directory location has to be specified separately while creating the unmanaged table. It provides the flexibility of storing the data at preferred location.
Major difference between managed and unmanaged table comes when you drop the table. In case of managed table, both metadata and data is deleted. Whereas in case of unmanaged table, only metadata is deleted.
Dataframe and Dataset Tranformations
Spark read the data and create either of the following:
- Data frame — programmatic data interface used from Spark program
- Database Table — SQL data interface used from Spark SQL
Following are the transformation applied on the data
- Combining one or more Data Frames using operations like join and union
- Aggregating and Summarizing data frames using operations like grouping, windowing and rollups
- Applying functions and built-in transformations using operations like filtering, sorting, splitting, sampling and finding unique
- Using Built-in functions, column-level functions and user defined functions (UDFs)
- Referencing rows/columns and creating custom expressions
Aggregations
Aggregations are a way to group data together to look at it from a higher level. In an aggregation, a key or grouping and an aggregation function specifies how to transform one or more columns. This function must produce one result for each group, given multiple input values. In general, aggregations are used to summarize numerical data usually by means of some grouping. This might be a summation, a product, or simple counting. Aggregation can be performed on tables, joined tables, views, etc.
In addition to working with any type of values, Spark allows to create the following groupings types:
- The simplest grouping is to just summarize a complete DataFrame by performing an aggregation in a select statement.
- A groupBy allows to specify one or more keys as well as one or more aggregation functions to transform the value columns.
- A window gives the ability to specify one or more keys as well as one or more aggregation functions to transform the value columns. However, the rows input to the function are somehow related to the current row.
- A grouping set, which can be used to aggregate at multiple different levels.
Joins
Spark join is about combining 2 or more different tables(sets) to get 1 set of the result based on some criteria. Joining of data is the most common usage of any ETL applications but also is the most tricky and compute heavy operation. Currently, Spark offers the following join types:
- Inner Join removes all the things that are not common in both the tables and is the default join in Spark.
- Left Join returns all the rows from the left table irrespective of whether there is a match in the right side table.
- Right Join returns all the rows from the right table irrespective of whether there is a match in the left side table.
- Outer Join returns all the records from both the tables along with the associated null values in the respective left/right tables.
- Cross Join returns a cartesian product of 2 tables.
- Left-Semi Join returns only the data from the left side that has a match on the right side based on the condition provided for the join statement. In contrast to Left join, right side table data is not present in the output.
- Left-Anti-Semi Join does exactly the opposite of Left semi-join. The output returns the data that does NOT have a match on the right side table. Only the columns on the left side table would be included in the result.
- In Self Join dataframe is joined with itself. To access the individual columns without name collisions, aliasing the dataframe is used.
References
- Spark Programming in Python for Beginners — Udemy, Prashant Kumar Pandey
- Spark: The Definitive Guide by Bill Chambers, Matei Zaharia, O’Reilly
- Apache Spark
- Databricks