
Apache Storm is a free and open source distributed realtime computation system. Apache Storm makes it easy to reliably process unbounded streams of data, doing for realtime processing what Hadoop did for batch processing.
Apache Storm cluster runs Topologies, which processes messages forever.
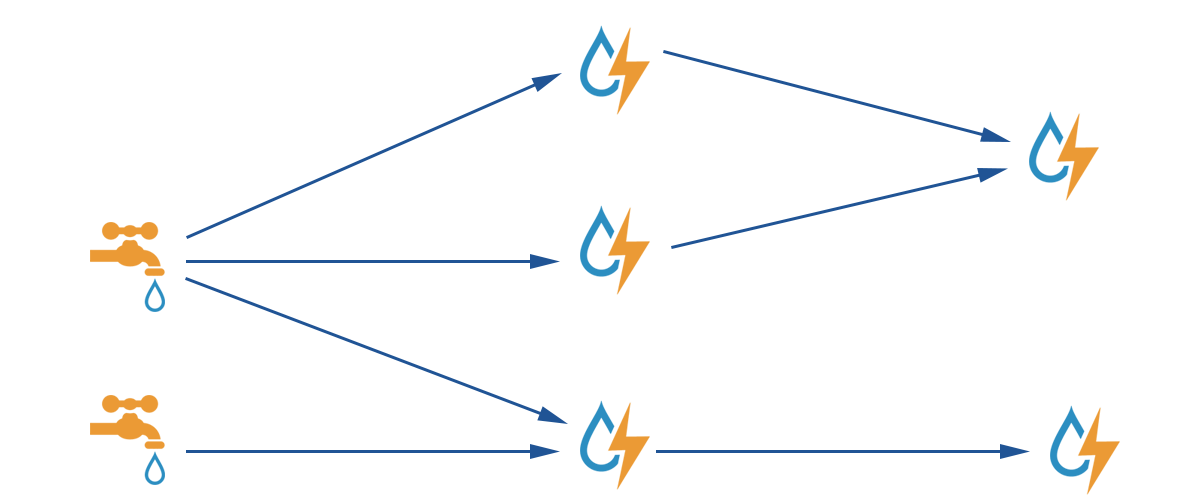
Components of Storm Cluster
Storm cluster consists of two kinds of nodes (master node and worker node) along with a resource manager (Zookeeper).
- master node — runs a daemon called “Nimbus”, which is responsible for distributing code around the cluster, assigning tasks to machines, and monitoring for failures
- worker node — runs a daemon called “Supervisor”, which listens for work assigned to its machine and starts and stops worker processes as necessary based on what Nimbus has assigned to it.
- Resource Manager — All coordination between Nimbus and the Supervisors is done through a Zookeeper cluster.
Also, “Nimbus” daemon and “Supervisor” daemons are fail-fast and stateless; all state is kept in Zookeeper or on local disk. This design leads to Storm clusters being incredibly stable.
Topology
The logic for a realtime application is packaged into a Storm topology. A topology is a graph of spouts and bolts that are connected with stream groupings. These concepts are described below:
Streams
A Stream is an unbounded sequence of tuples that is processed and created in parallel in a distributed fashion. Streams are defined with a schema that names the fields in the stream’s tuples. Every stream is given an id when declared.
Spouts
A Spout is a source of streams in a topology. Generally spouts will read tuples from an external source and emit them into the topology. Spouts can either be reliable or unreliable. A reliable spout is capable of replaying a tuple if it failed to be processed by Storm, whereas an unreliable spout forgets about the tuple as soon as it is emitted.
Spouts can emit more than one stream by declare multiple streams using the declareStream method of OutputFieldsDeclarer and specify the stream to emit to when using the emit method on SpoutOutputCollector.
The main method on spouts is nextTuple, which either emits a new tuple into the topology or simply returns if there are no new tuples to emit. nextTuple does not block because Storm calls all the spout methods on the same thread.
The other important methods on spouts are ack and fail, which are called only for reliable spouts. These are called when Storm detects that a tuple emitted from the spout either successfully completed through the topology or failed to be completed.
Bolts
All processing in topology is done in bolts. Bolts can do anything from filtering, functions, aggregations, joins, talking to databases, and more.
Bolts can emit more than one stream. To do so, declare multiple streams using the declareStream method of OutputFieldsDeclarer and specify the stream to emit to when using the emit method on OutputCollector.
The main method in bolts is the execute method which takes in as input a new tuple. Bolts emit new tuples using the OutputCollector object. Bolts must call the ack method on the OutputCollector for every tuple they process so that Storm knows when tuples are completed. Its perfectly fine to launch new threads in bolts that do processing asynchronously as OutputCollector is thread-safe and can be called at any time.
Stream Groupings
A stream grouping defines how that stream should be partitioned among the bolt’s tasks. There are eight built-in stream groupings in Storm:
- Shuffle grouping: Tuples are randomly distributed across the bolt’s tasks in a way such that each bolt is guaranteed to get an equal number of tuples.
- Fields grouping: The stream is partitioned by the fields specified in the grouping. For example, if the stream is grouped by the “user-id” field, tuples with the same “user-id” will always go to the same task, but tuples with different “user-id”’s may go to different tasks.
- Partial Key grouping: The stream is partitioned by the fields specified in the grouping, like the Fields grouping, but are load balanced between two downstream bolts, which provides better utilization of resources when the incoming data is skewed.
- All grouping: The stream is replicated across all the bolt’s tasks.
- Global grouping: The entire stream goes to a single one of the bolt’s tasks. Specifically, it goes to the task with the lowest id.
- None grouping: This grouping specifies that you don’t care how the stream is grouped. Currently, none groupings are equivalent to shuffle groupings.
- Direct grouping: This is a special kind of grouping. A stream grouped this way means that the producer of the tuple decides which task of the consumer will receive this tuple. Direct groupings can only be declared on streams that have been declared as direct streams. Tuples emitted to a direct stream must be emitted using one of the emitDirect methods.
- Local or shuffle grouping: If the target bolt has one or more tasks in the same worker process, tuples will be shuffled to just those in-process tasks. Otherwise, this acts like a normal shuffle grouping.
Components Running a Topology
Storm distinguishes between the main entities that are used to run a topology in a Storm cluster:
- Worker processes
- Executors (threads)
- Tasks
Here is a simple illustration of their relationships:
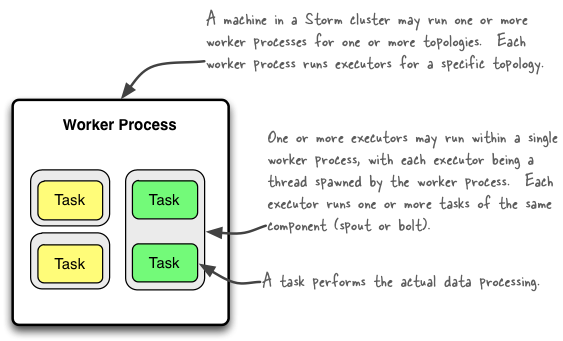
A worker process executes a subset of a topology. A worker process belongs to a specific topology and may run one or more executors for one or more components (spouts or bolts) of this topology. A running topology consists of many such processes running on many machines within a Storm cluster.
An executor is a thread that is spawned by a worker process. It may run one or more tasks for the same component (spout or bolt).
A task performs the actual data processing — each spout or bolt that you implement in your code executes as many tasks across the cluster. The number of tasks for a component is always the same throughout the lifetime of a topology, but the number of executors (threads) for a component can change over time. This means that the following condition holds true: #threads ≤ #tasks . By default, the number of tasks is set to be the same as the number of executors, i.e. Storm will run one task per thread.
Example of a running topology
The following illustration shows how a simple topology would look like in operation. The topology consists of three components: one spout called BlueSpout and two bolts called GreenBolt and YellowBolt. The components are linked such that BlueSpout sends its output to GreenBolt, which in turns sends its own output to YellowBolt.
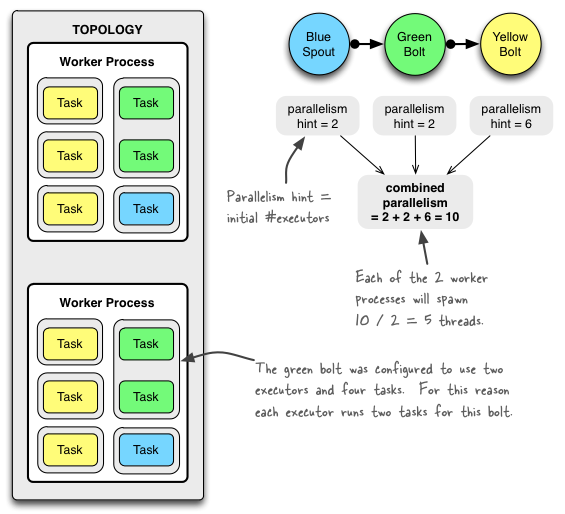
The GreenBolt was configured as per the code snippet above whereas BlueSpout and YellowBolt only set the parallelism hint (number of executors). Here is the relevant code:

How to change the parallelism of a running topology
A nifty feature of Storm is that you can increase or decrease the number of worker processes and/or executors without being required to restart the cluster or the topology. The act of doing so is called rebalancing.
There are two options to rebalance a topology:
- Use the Storm web UI to rebalance the topology.
- Use the CLI tool storm rebalance as described below.
Here is an example of using the CLI tool:
## Reconfigure the topology "mytopology" to use 5 worker processes,
## the spout "blue-spout" to use 3 executors and
## the bolt "yellow-bolt" to use 10 executors.
$ storm rebalance mytopology -n 5 -e blue-spout=3 -e yellow-bolt=10
Data Model
Storm uses tuples as its data model. A tuple is a named list of values, and a field in a tuple can be an object of any type.
Every node in a topology must declare the output fields for the tuples it emits. For example, this bolt declares that it emits 2-tuples with the fields “double” and “triple”:
public class DoubleAndTripleBolt extends BaseRichBolt {
private OutputCollectorBase _collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollectorBase collector) {
_collector = collector;
}
@Override
public void execute(Tuple input) {
int val = input.getInteger(0);
_collector.emit(input, new Values(val*2, val*3));
_collector.ack(input);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("double", "triple"));
}
}
The declareOutputFields function declares the output fields ["double", "triple"] for the component.
Topology Example
Following is an example of Word count topology to understand how the above concepts comes together.
In this topology there are two processing units WordSpout — generates random words pick from a array and emits them as “word” in the function nextTuple() CountBolt — picks the each tuple by field “word” and process it to display output in the form “word:count”
WordSpout.java
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import java.util.Map;
public class WordSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
private String[] words = {"hello","world","storm","study"};//word pool
private int index = 0;
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {
this.collector = spoutOutputCollector;
}
public void nextTuple() {
this.collector.emit(new Values(this.words[index]));
index++;
if (index >= words.length) {
index = 0;
}
// wait for 500ms
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("word"));
}
}
CountBolt.java
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class CountBolt extends BaseRichBolt {
private HashMap<String, Integer> wordMap = new HashMap<String, Integer>();
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
}
public void execute(Tuple tuple) {
// read words from tuple
String word = tuple.getStringByField("word");
// count
int num;
if (wordMap.containsKey(word)) {
num = wordMap.get(word);
} else {
num = 0;
}
wordMap.put(word, 1 + num);
// display output
Set<String> keys = wordMap.keySet();
for (String key: keys) {
System.out.print(key + ":" + wordMap.get(key) + ",");
}
System.out.println();
}
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
}
}
MainTopology.java
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.topology.TopologyBuilder;
public class MainTopology {
public static void main(String[] args) throws Exception {
MainTopology topology = new MainTopology();
topology.runLocal(60);
}
public void runLocal(int waitSeconds) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("wordSpout", new WordSpout(), 1);
builder.setBolt("countBolt", new CountBolt(), 1)
.shuffleGrouping("wordSpout");
Config config = new Config();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("word_count", config, builder.createTopology());
try {
Thread.sleep(waitSeconds * 1000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
cluster.killTopology("word_count");
cluster.shutdown();
}
}
Output
hello:1,
world:1,hello:1,
12:07:22.669 [timer] INFO o.a.s.s.b.BlacklistScheduler - Supervisors [] are blacklisted.
world:1,storm:1,hello:1,
study:1,world:1,storm:1,hello:1,
12:07:23.687 [timer] INFO o.a.s.s.b.BlacklistScheduler - Supervisors [] are blacklisted.
study:1,world:1,storm:1,hello:2,
study:1,world:2,storm:1,hello:2,
12:07:24.707 [timer] INFO o.a.s.s.b.BlacklistScheduler - Supervisors [] are blacklisted.
study:1,world:2,storm:2,hello:2,
study:2,world:2,storm:2,hello:2,
12:07:25.721 [timer] INFO o.a.s.s.b.BlacklistScheduler - Supervisors [] are blacklisted.
study:2,world:2,storm:2,hello:3,
study:2,world:3,storm:2,hello:3,
12:07:26.739 [timer] INFO o.a.s.s.b.BlacklistScheduler - Supervisors [] are blacklisted.
study:2,world:3,storm:3,hello:3,
study:3,world:3,storm:3,hello:3,
study:3,world:3,storm:3,hello:4,
12:07:27.752 [timer] INFO o.a.s.s.b.BlacklistScheduler - Supervisors [] are blacklisted.
study:3,world:4,storm:3,hello:4,
study:3,world:4,storm:4,hello:4,
12:07:28.771 [timer] INFO o.a.s.s.b.BlacklistScheduler - Supervisors [] are blacklisted.
study:4,world:4,storm:4,hello:4,
study:4,world:4,storm:4,hello:5,
12:07:29.781 [timer] INFO o.a.s.s.b.BlacklistScheduler - Supervisors [] are blacklisted.
study:4,world:5,storm:4,hello:5,
study:4,world:5,storm:5,hello:5,
12:07:30.792 [timer] INFO o.a.s.s.b.BlacklistScheduler - Supervisors [] are blacklisted.
study:5,world:5,storm:5,hello:5,
study:5,world:5,storm:5,hello:6,
12:07:31.804 [timer] INFO o.a.s.s.b.BlacklistScheduler - Supervisors [] are blacklisted.
study:5,world:6,storm:5,hello:6,
study:5,world:6,storm:6,hello:6,